As a means of human-computer interaction, the endpoint detection of speech is of great significance in the liberation of human hands. At the same time, there are various background noises in the working environment, which will seriously reduce the quality of the speech and affect the effect of the speech application, such as reducing the recognition rate. Uncompressed voice data, network traffic in network interactive applications is too large, thus reducing the success rate of voice applications. Therefore, audio endpoint detection, noise reduction and audio compression have always been the focus of terminal speech processing and are still active research topics.
In order to understand the basic principles of endpoint detection and noise reduction, let you take a peek at the mystery of audio compression. Li Hongliang, senior research and development engineer of Keda Xunfei, will explain the hotspots in speech processing detection technology - endpoint detection and noise reduction. And compression.
â–ŽEndpoint detection
First look at the endpoint detection (Voice AcTIvity DetecTIon, VAD). Audio endpoint detection is the detection of valid speech segments from a continuous stream of speech. It includes two aspects, detecting the starting point of the effective speech, that is, the front end point, and detecting the end point of the effective speech, that is, the rear end point.
It is necessary to perform endpoint detection of speech in a voice application. The first simple point is to separate the effective voice from the continuous voice stream in the scenario of storing or transmitting voice, which can reduce the amount of data stored or transmitted. Secondly, in some application scenarios, the use of endpoint detection can simplify human-computer interaction. For example, in a recorded scene, the endpoint detection after speech can omit the operation of ending the recording.
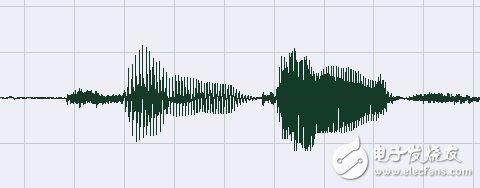
In order to more clearly explain the principle of endpoint detection, first analyze a piece of audio. The above picture is a simple audio with only two words. It can be seen intuitively from the figure that the amplitude of the sound wave in the silent part of the head and tail is small, and the amplitude of the effective speech part is relatively large. The amplitude of a signal is visually represented. The size of the signal energy: the energy value of the mute part is small, and the energy value of the effective speech part is large. The speech signal is a one-dimensional continuous function with time as the independent variable. The computer-processed speech data is a sequence of sampled values ​​of the speech signal sorted by time. The magnitude of these sample values ​​also represents the energy of the speech signal at the sampling point.

There are positive and negative values ​​in the sampled values. It is not necessary to consider the sign when calculating the energy value. In this sense, it is natural to use the absolute value of the sampled value to represent the energy value, because the absolute value symbol is mathematically processed. Inconvenient, the energy value of the sampling point usually uses the square of the sampled value, and the energy value of a speech containing N sampling points can be defined as the sum of the squares of each sampled value.
Thus, the energy value of a speech is related to both the size of the sample and the number of samples contained therein. In order to investigate the change of the speech energy value, the speech signal needs to be segmented according to a fixed duration, for example, 20 milliseconds. Each segmentation unit is called a frame, and each frame contains the same number of sampling points, and then the energy value of each frame of speech is calculated.
If the energy value of the continuous M0 frame in the front part of the audio is lower than a predetermined energy value threshold E0, and the next continuous M0 frame energy value is greater than E0, the voice energy value is increased at the front end point of the speech. Similarly, if the continuous speech energy values ​​of several frames are large, and the subsequent frame energy values ​​become smaller and last for a certain length of time, it can be considered that the position of the energy value is the rear end point of the speech.
The question now is, how is the energy value threshold E0 taken? What is M0? The ideal mute energy value is 0, so the E0 in the above algorithm takes 0 in the ideal state. Unfortunately, scenes that collect audio often have a certain intensity of background sound. This simple background sound is of course muted, but its energy value is obviously not zero. Therefore, the actual collected audio usually has a certain background sound. Base energy value.
We always assume that the collected audio has a small silence at the beginning, usually a few hundred milliseconds in length. This small silence is the basis of our estimated threshold E0. Yes, it is always assumed that a small piece of speech at the beginning of the audio is muted, which is very important! ! ! ! This assumption is also used in the subsequent noise reduction introduction. When estimating E0, a certain number of frames such as the first 100 frames of speech data (these are "mute") are selected, the average energy value is calculated, and then an empirical value is added or multiplied by a coefficient greater than 1, thereby obtaining E0. This E0 is the benchmark for us to judge whether a frame of speech is muted. If it is greater than this value, it is a valid voice. If it is less than this value, it is muted.
As for M0, it is easier to understand, and its size determines the sensitivity of the endpoint detection. The smaller the M0, the higher the sensitivity of the endpoint detection, and vice versa. The scene of the speech application should be different, and the sensitivity of the endpoint detection should also be set to a different value. For example, in the application of the voice-activated remote controller, since the voice command is generally a simple control command, there is little possibility of a long pause such as a comma or a period in the middle, so it is reasonable to improve the sensitivity of the endpoint detection, and M0 is set to be relatively Small value, the corresponding audio duration is generally about 200-400 milliseconds. In a large-scale speech dictation application, because there is a long pause in the middle such as a comma or a period, the sensitivity of the endpoint detection should be reduced. At this time, the M0 value is set to a larger value, and the corresponding audio duration is generally 1500-3000. millisecond. Therefore, the value of M0, that is, the sensitivity of the endpoint detection, should be made adjustable in practice, and its value should be selected according to the scene of the voice application.
The above is just a simple general principle of voice endpoint detection. The algorithm in practical application is far more complicated than the above. As a widely used speech processing technology, audio endpoint detection is still a more active research direction. The University of Science and Technology has used Recurrent Neural Networks (RNN) technology to perform endpoint detection of speech. The actual effect can be focused on Xunfei's products.
15+ Years Experience Manufacturing, ITOPNOO Provide One-stop Smart Wearable devices Solutions For You.
Our Smart Wearable products include android smart watches, Watch For iPhone, Bracelet and Wristband etc.
Leading healthcare navigation services for individuals and families who are generally healthy or face serious medical issues, and health services for employers.
The Trends New Watches Designs. Custom smart watch products designed with the vision of our clients' brands in mind.
Best Smartwatch,Best Smart Watches,Kids Smart Watch,Noise Smart Watch
TOPNOTCH INTERNATIONAL GROUP LIMITED , https://www.mic11.com