Li Qiujing, Ye Yun, ZTE Corporation
Abstract: Combining a number of actual cases around the world, this paper proposes a streamlined scheme architecture for telecommunication big data. The solution is based on the actual application scenario of the operator, selecting suitable components for combination, and eliminating the generalized platform. The development of big data requires improving the operational efficiency through the application of big data, and the second is to expand the new service content through Data as a Service (DAAS) and provide external services. In the business implementation process, capturing, managing, and tapping the telecom operators' core data is the basis. The rapid deployment and application of operators' big data is the ultimate goal. Both need to be balanced in terms of efficiency, cost, and time.
Keywords: Big Data; Telecommunications Networks; Streamlined Architecture; Data as a Service
1 Telecom operators build big data ideas and key technologies
The operator's network and user are the core assets of the operator. The data (including user configuration basic data, network signaling data, network management/log data, user location data, and terminal information) are the core data assets of the operator. For operators, the most valuable data comes from the basic telecommunication network itself. The mining and analysis of basic pipeline data is the most important direction of operators' big data mining. It is imperative for operators to grab, manage and mine these data [1-2]. Operators can use big data applications based on core data from two perspectives:
(1) Improve its operational efficiency through big data applications. Typical applications include: signaling multi-dimensional analysis, comprehensive network management and analysis, business and operations support system (BOSS) operations, comprehensive analysis, and precision marketing.
(2) Expand new service content through Data as a Service (DAAS) and provide external services. Including individual and group location information and user behavior analysis, etc. are very valuable information for third-party companies (such as retail or consulting companies, government, etc.). Operators can provide external DAAS services based on these data and expand market space.
In order to build telecommunication operations, big data applications can be divided into data collection and storage, information retrieval convergence, knowledge discovery, and intelligence from the perspective of technical capabilities. The telecommunication big data technology level is shown in Figure 1. From the bottom up, the depth of data mining has increased and the difficulty has increased. The demand for intelligent systems has increased. Key technologies include extracting transform loads (ETL), parallel computing frameworks, distributed databases, distributed file systems, data mining, and machine learning.
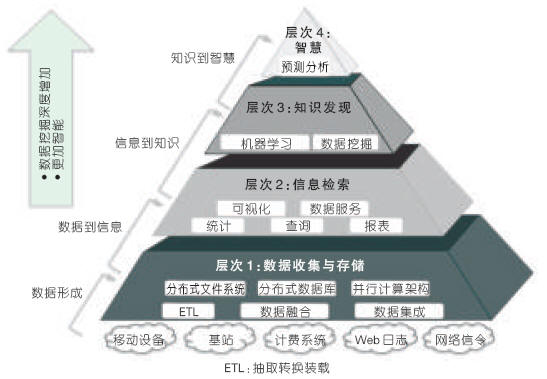
Figure 1 Telecommunication big data technology level
In the face of massive amounts of big data, how to effectively handle data processing is an urgent problem that needs to be solved. Distributed parallel processing is an effective means. Traditional relational databases mostly use the sharing-disk architecture. When the data volume reaches a certain level, it will face the "bottleneck" of processing and the difficulty of expansion, and the cost is also high. The current effective approach is to use Distributed File System/Distributed Database in combination with distributed parallel processing. Currently, the open source Hadoop platform is a widely used implementation solution in the industry. The core idea of ​​Hadoop [3] is based on Hadoop Distributed File System (HDFS) storage files or based on HBase database (also based on HDFS), using the distributed parallel computing framework MapReduce to perform distributed Map operations and Reduce reduction operations in parallel. In Hadoop's computing model, compute nodes and storage nodes are combined. Ordinary PC servers that store data can perform MapReduce tasks. In the Sharing-disk model, the storage node is separate from the compute node. The stored data needs to be transmitted to the compute node for calculation. The Hadoop calculation model is suitable for offline batch processing scenarios, such as log log analysis, document statistics analysis, and so on. It is a useful complement to the relational database management system (RDBMS).
In the private technology to achieve distributed storage and parallel processing, in the call interface compatible with Hadoop, this is a feasible technical solution. This solution can avoid the above Hadoop shortcomings, while doing more optimization on the performance. Effective means include increasing the Data Locality feature, reducing data transfer between different nodes in multiple iterative calculations, and using indexing and caching to speed up data processing. The combination of storage and computing hardware for tuning is also an effective method. It can use hierarchical storage of data and distribute the data on different media such as memory, solid-state hard disk (SSD), hard disk, etc. [4], making it very good for computing resources. balance.
In the face of the real-time requirements of massive data, a more effective way is to use complex event processing (CEP) [5]. The real-time stream processing adopts an event triggering mechanism to process the input events in memory in time. At the same time for a plurality of events can be synthesized an event [6]. Real-time streaming processing requires support rules to meet flexible event processing requirements. Real-time streaming processing can use distributed memory databases, message buses, and other mechanisms to achieve fast real-time response. Currently, there are many commercial CEP products, but there are great differences in function, performance, and scope of application. Selecting high maturity and suitable products are the key.
For large amounts of semi-structured or unstructured data in big data, NoSQL database emerged. The NoSQL database abandons the relational model, weakens transactions, supports mass storage, high scalability, high availability, and high concurrency requirements. The NoSQL database has high advantages in specific application scenarios and is an effective supplement to traditional databases. According to the data model, there are four major categories of NoSQL: Key-Value, Column Store, Document, and Graph, which correspond to different application scenarios. For example, the Key-Value type is suitable for efficient query of simple key-value pairs, and the graph type is suitable for storage and efficient query of social relations.
For the big data mining analysis, search and machine adaptive learning and other technologies in the enterprise system gradually applied. There are many types of related algorithms, and distributed mining and distributed search are the most demanding ones.
Due to changes in data types and data processing methods, the traditional ETL is no longer applicable. Operators need to make different plans according to the application scenario. At present, due to the large differences in operators' application systems, there has not yet been a unified processing model. One method that is more feasible is to perform layered processing according to the function and characteristics of the data. For example, a large number of data sources first perform preliminary screening, and after screening, some data enter the data warehouse or RDBMS or other applications. The initial screening can be done using Hadoop or CEP or custom.
Different operators or application scenarios require different technologies or combinations of technologies. For example, when a user looks up a single query in real time, the amount of data is huge, but its data type is simple, data is mainly read, and no complicated Join operation is required, and the data distribution is good. Using Hadoop can greatly improve query performance and reduce processing costs compared to traditional RDBMS. More applications may require a combination of technologies. For example, signaling acquisition and multi-dimensional analysis, signaling data, especially packet domain (PS) signaling data volume and high real-time requirements, effective solution to massive data processing and real-time requirements is its key, the need for CEP and Hadoop combination. In the current stage, different technologies have different levels of maturity. Due to the rapid progress in the application of big data in the industry, we believe that the current simplified solution for different applications is the most appropriate, that is, according to the application scenario, select the most appropriate components to do the combination and discard. Generalized platform.
2 ZTE Big Data Practice
Relying on long-term accumulation in the cloud computing and other fields, ZTE has formed a complete technical architecture for Big Data. The ZTE big data technology architecture is shown in Figure 2. According to the different application requirements of operators, the architecture emphasizes the use of component building methods to form an end-to-end solution. The following is a description of two specific cases.
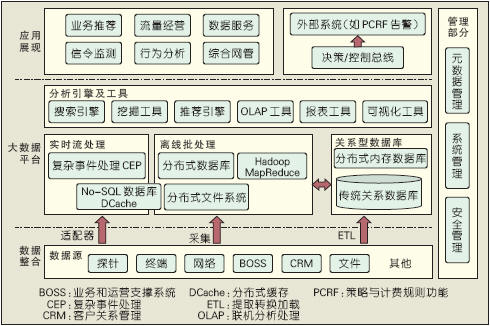
Figure 2 ZTE Big Data Technology Architecture
(1) User real-time location information service system
The system collects the dynamic location information of the cellular network users in real time and provides DAAS services through the standard interface. In actual projects, the number of users accessing the current period reached more than 20 million, and the daily user location update data can reach more than 4 billion, and the peak period update reaches hundreds of thousands of times per second. In addition to the collected location, it can also be analyzed in combination with other data sources such as the age of the user, and the application programming interface (API) is open to the upper application. In addition, the system needs to have good scalability, and it can subsequently access data sources in other regions. In addition, this system needs to have a good price/performance ratio, controllable cost, and controllable time. Based on these requirements, we built a system based on the mature component KV NoSQL database. The user real-time location information service system is shown in Figure 3.
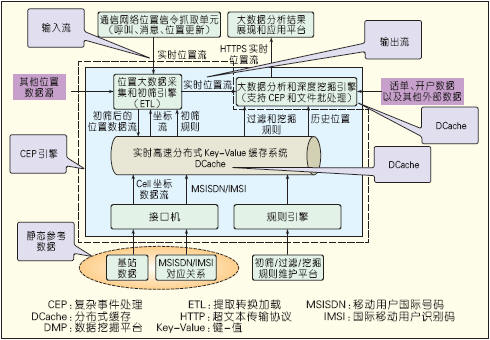
Figure 3 User real-time location information service system
The user real-time location information service system is a typical streamlining scheme. It is based on the distributed cache (DCache) of the distributed Key-Value NoSQL database and assembles a system for real-time processing of location stream events. DCache is both a message bus and an in-memory database and can well meet the requirements of real-time. At the same time, DCache is based on x86 blade servers and adopts a distributed architecture. The system has good scalability and low cost. The system is superior in performance, stable and reliable, and has achieved good results.
(2) Signaling Monitoring Multidimensional Analysis System
With the rapid growth of carrier data services, operators have greater pressure on network quality and network operation efficiency. By collecting the network Gn interface and Mc interface signalling and processing analysis, a complete view of the network operation can be obtained, and related thematic analysis based on signaling, such as network quality analysis, traffic efficiency analysis, multi-network collaborative analysis, customer complaints and service analysis. Such as the operator's network operation has great value.
The difficulty of multi-dimensional analysis of signaling monitoring is that the signaling traffic is large and the data volume is large. For example, the peak traffic of a company's Gn interface can reach 4 Gb/s, and the daily signaling data can reach 1 TB. Need to collect signaling and do a variety of analysis to serve different departments.
Signaling Monitoring Multidimensional Analysis System uses a layered architecture to facilitate data sharing and application expansion. The signaling monitoring multidimensional analysis system is shown in Figure 4. Use real-time streaming to meet real-time high data analysis requirements. Use the traditional RDBMS storage for subsequent analysis queries for data that is initially processed by a session or transaction detail (XDR). The XDR with a large amount of data is stored and queried using Hadoop HBase, and the original signaling is stored locally using a distributed file system.
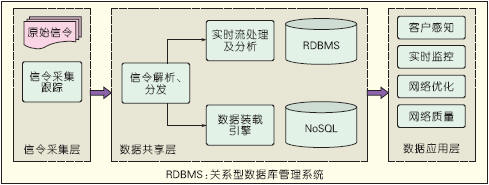
Figure 4 Signaling Monitoring Multidimensional Analysis System
In this solution, the data is stored and processed in different ways according to its usage characteristics, which breaks through the "bottleneck" and scalability "bottleneck" of RDBMS and achieves very good results. In the test, the 4-node PC server can fully bear the storage of the PS domain XDR of an operator-provider province company, and the storage performance can reach 50 Mb/s. The query can be returned within 10 s for hundreds of billions of record inquiries. Has achieved very good practical results.
3 Conclusion
Telecom operators are facing the opportunity of big data development and are actively promoting trials and commercialization of big data. Under the current situation of rapid development of big data technology, building a streamlined plan according to requirements and application scenarios can help operators quickly gain competitive advantage in the current fiercely competitive environment and achieve the best balance in efficiency, cost, and time.
references
[1] Cisco Systems. Cisco visual networking index global mobile data traffic forecast update, 2011 - 2016 [EB/OL]. [2013-03-25]. http://
[2] MANYIKA J, CHUI M, BROWN B, et al. Big data: The next frontier for innovation, competition, and productivity [R]. McKinsey Global Institute, 2011.
[3] WHITE T. Hadoop Definitive Guide [M]. 2nd edition. Zhou Minqi, Wang Xiaoling, Jin Cheqing, translation. Beijing: Tsinghua University Press, 2011.
[4] SNIA. 2012 SNIA Sprint Tutorials-NextGen Infrastructure for Big Data [EB/OL]. [2013-02-15]. http://
[5] NEUMEYER L, ROBBINS B, NAIR A, et al. S4: Distributed stream computing platform [C]// Proceedings of the IEEE International Conference on Data Mining Workshops (ICDMW'10), Dec 14-17, 2010, Sydney , Australia .Los Alamitos, CA, USA: IEEE Computer Society, 2010: 170-177.
[6] SHARON G, ETZION O. Event-processing network model and implementation [J]. IBM Systems Journal, 2008, 47(2):321-334.
Custom manufacturer of CNC fabricated wood parts for industrial purposes. Available in a variety of specifications. Services include bending, forming, tube bending, waterjet cutting, machining, welding, weldments, and machine building. Can accommodate a wide variety of fabrications, including large or small parts and assemblies. Assembly, prototype, finishing, design, and engineering services are also offered.
Phenolic Paper Sheet Customized Parts
Phenolic Paper Sheet,Phenolic Machined Parts,Phenolic Paper Machined,Phenolic Paper Sheet Machined Parts
Yingkou Dongyuan Electrical Insulation Board Co.,Ltd , https://www.dy-insulation.com