This article compares the three video standards of MPEG-2 video standard, MPEG-4 AVC / H.264 and AVS video (GB / T 200090.2) from a technical perspective, including technical solutions, subjective testing, objective testing, and complexity. Aspects.
1. Technical comparison
Both AVS video and MPEG standards use a hybrid coding framework (see Figure 1), which includes transformation, quantization, entropy coding, intra prediction, inter prediction, loop filtering and other technical modules. This is the current mainstream technical route. The main innovation of AVS lies in proposing a number of specific optimization techniques, achieving technical performance equivalent to international standards at a lower complexity, but not using a large number of complex patents behind international standards. The characteristic core technologies in AVS-video include: 8x8 integer transform, quantization, intra prediction, 1/4 precision pixel interpolation, special inter prediction motion compensation, two-dimensional entropy coding, deblocking in-loop filtering, etc.
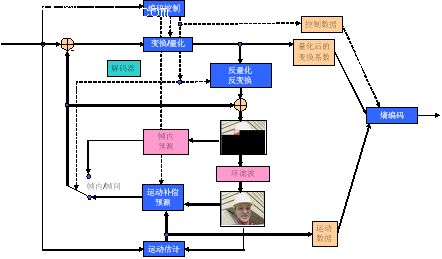
Figure 1 Typical video coding framework
The block diagram of the AVS video encoder is shown below.
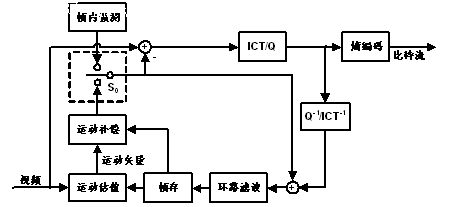
Figure 2 AVS video encoder block diagram
The AVS video standard defines three different types of images: I frame, P frame, and B frame. The macro blocks in the I frame only perform intra prediction, and the macro blocks in the P frame and B frame require intra prediction or inter prediction. In the figure, S0 is the prediction mode selection switch. The prediction residual is subjected to 8ï‚´8 integer transform (ICT) and quantization, and then the zig-zag scan is performed on the quantized coefficients (another scanning method is used for interlaced coding blocks) to obtain one-dimensional array of quantized coefficients, and finally the entropy of the quantized coefficient coding. The transformation and quantization of the AVS video standard only requires addition and subtraction and shift operations, which can be completed with 16-bit precision.
The AVS video standard uses a loop filter to filter the reconstructed image, on the one hand, it can eliminate the square effect and improve the subjective quality of the reconstructed image; on the other hand, it can improve the coding efficiency. The filter strength can be adjusted adaptively.
The AVS standard supports multiple video services. Considering the interoperability between different services, the AVS standard defines a profile and a level. The grade is a subset of the grammar, semantics and algorithms defined by AVS; the grade is a limited set of grammatical elements and grammatical element parameter values ​​under a certain grade. In order to meet the needs of high-definition / standard-definition digital TV broadcasting, digital storage media and other services, the AVS video standard defines a benchmark profile (Jizhun profile) and 4 levels (4.0, 4.2, 6.0, and 6.2), and supports the largest images The resolution is from 720576 to 19201080, and the maximum bit rate is from 10 Mbit / s to 30 Mbit / s.
Table 1 Technical comparison and performance difference estimation between AVS and MPEG-2, MPEG-4 AVC / H.264
Video coding standard | MPEG-2 video | MPEG-4 AVC / H.264 video | AVS video | Estimation of performance difference between AVS video and AVC / H.264 (Adopts the signal-to-noise ratio dB estimation, the percentage in brackets is the difference in code rate) |
Intra prediction | DC coefficient differential prediction only in the frequency domain | Based on 4 & TImes; 4 blocks, 9 luma prediction modes, 4 chroma prediction modes | Based on 8 & TImes; 8 blocks, 5 luma prediction modes, 4 chroma prediction modes | Basically equivalent |
Multi-reference frame prediction | Only 1 frame | Up to 16 frames | Up to 2 frames | When both frames are used, the performance is not obvious when the number of frames increases. |
Variable block size motion compensation | 16 & TImes; 16 16 & TImes; 8 (field coding) | 16 × 16, 16 × 8, 8 × 16, 8 × 8, 8 × 4, 4 × 8, 4 × 4 | 16 × 16, 16 × 8, 8 × 16, 8 × 8 | Decrease about 0.1dB (2-4%) |
B frame macroblock direct coding mode | no | Independent spatial or temporal prediction mode, if the block used to derive the motion vector in the backward reference frame is intra-coded, it is still used for prediction if the motion vector is 0 | Combining the time domain and space domain, when the block used to derive the motion vector in the backward reference frame in the time domain is intra-coded, the motion vectors of adjacent blocks in the space domain are used for prediction | Increase 0.2-0.3dB (5%) |
B-frame macroblock bidirectional prediction mode | Two motion vectors before and after encoding | Two motion vectors before and after encoding | Called symmetric prediction mode, only one forward motion vector is encoded, and the backward motion vector is derived from the forward direction | Basically equivalent |
¼ pixel motion compensation | Bilinear interpolation only at half-pixel positions | ½ pixel position adopts 6 beat filtering, ¼ pixel position linear interpolation | ½ pixel position uses 4-beat filtering, ¼ pixel position uses 4-beat filtering, linear interpolation | Basically equivalent |
Transformation and quantization | 8 × 8 floating point DCT transform, division and quantization | For 4 × 4 integer transform, both the codec and the decoder need to be normalized. The combination of quantization and transform normalization is realized by multiplication and shift. | 8 × 8 integer transform, transform normalization at the encoding end, combining quantization and transform normalization, through multiplication and shift | Increase about 0.1dB (2%) |
Entropy coding | Single VLC meter, poor adaptability | CAVLC: High correlation with surrounding blocks, complicated implementation CABAC: The calculation is more complicated | Context-adaptive 2D-VLC, multi-code table switching during encoding block coefficients | Reduce about 0.5dB (10-15%) |
Loop filtering | no | Based on 4 × 4 block edges, there are many filter intensity classifications and complex calculations | Based on 8 × 8 block edges, simple filtering intensity classification, filtering less pixels, and low calculation complexity | —— |
Fault-tolerant coding | Simple striping | Data segmentation, complex FMO / ASO and other macro blocks, strip organization mechanism, forced Intra block refresh coding, constrained intra prediction, etc. | A simple striping mechanism is sufficient to meet the needs of error concealment and recovery in broadcast applications | —— |
DCT (Discrete Cosine Transform): Discrete Cosine Transform
VLC (Variable Length Coding): variable length coding
CAVLC (Context-based Adaptive Variable Length Coding): Context-based Adaptive Variable Length Coding
CABAC (Context-based Adaptive Binary Arithmetic Coding): Context-based Adaptive Binary Arithmetic Coding
FMO (Flexible Macroblock Ordering): Flexible macroblock ordering
ASO (Arbitrary Slice Ordering): Arbitrary slice arrangement
Second, subjective evaluation and objective test compression effect evaluation standards are subjective evaluation and objective evaluation, each has advantages and disadvantages. Subjective evaluation is to hire a special evaluator to compare the difference between the audio-visual effect recovered after compression and the original effect, usually subjective scoring according to certain rules in a special audio-visual environment. The objective judgment is to calculate the loss of multimedia data compression results through a specific algorithm, such as the signal-to-noise ratio SNR (that is, the logarithm of the signal-to-noise ratio). Subjective and objective judgments are sometimes quite different, so measuring the quality of an algorithm requires finding a balance between the two. For a set of standard evaluations, the objective evaluation method is usually used in the development process, but ultimately it needs to be confirmed by the subjective evaluation.
Neon Led Strip,Purple Neon Lights,Neon Light Signs Custom,Neon Lights For Bedroom
Tes Lighting Co,.Ltd. , https://www.neonflexlight.com