**Summary**
Machine learning has become one of the most exciting and rapidly evolving fields in data science. It's widely used across industries, from finance to healthcare, and even in everyday applications like recommendation systems or speech recognition. This article aims to provide a concise yet comprehensive overview of common machine learning algorithms, helping you better understand their purposes and how they can be applied in real-world scenarios.

There are numerous machine learning algorithms, and it can be challenging to know which one to choose for a specific task. To make things clearer, we’ll categorize them based on two main perspectives: the **learning method** and the **similarity of the algorithm**.
### Learning Methods
In machine learning, the way an algorithm learns is crucial. Different problems require different approaches, and understanding these learning methods helps in selecting the right tool for the job.
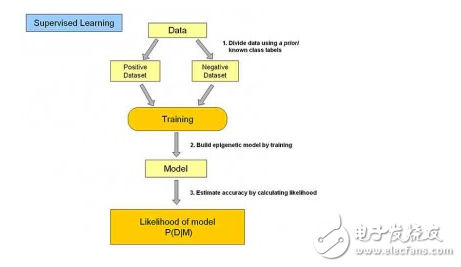
#### Supervised Learning
Supervised learning involves training a model using labeled data—data that comes with known outcomes. The model learns from this data and then applies what it has learned to new, unseen data. Common tasks include classification and regression. Examples of algorithms include **Logistic Regression**, **Neural Networks**, and **Support Vector Machines (SVM)**.
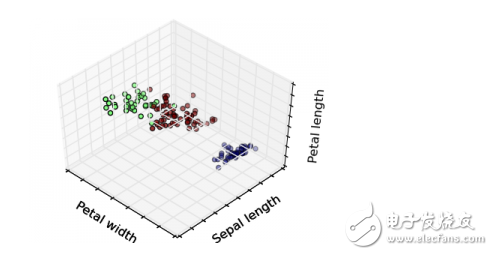
#### Unsupervised Learning
Unlike supervised learning, unsupervised learning deals with unlabeled data. The goal is to find hidden patterns or groupings within the data. Common use cases include clustering and association rule mining. Algorithms such as **k-Means Clustering** and **Apriori** fall into this category.
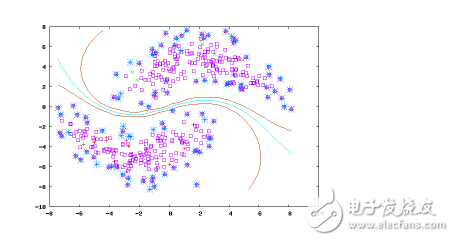
#### Semi-Supervised Learning
This approach combines both labeled and unlabeled data. It’s useful when there’s a small amount of labeled data but a large amount of unlabeled data. Algorithms like **Graph Inference** and **Laplacian SVM** are often used here.
#### Reinforcement Learning
Reinforcement learning is all about learning through interaction. The model learns by receiving rewards or penalties for its actions. It's commonly used in robotics and game playing. Popular algorithms include **Q-Learning** and **Temporal Difference Learning**.
In enterprise settings, **supervised and unsupervised learning** are the most commonly used. However, in areas like image recognition, where data is mostly unlabelled, **semi-supervised learning** becomes more relevant. **Reinforcement learning** is often applied in control systems and autonomous agents.
### Algorithm Similarity
Another way to classify algorithms is by their **function and structure**. This helps in understanding how different algorithms relate to each other and what types of problems they’re best suited for.
#### Regression Algorithms
Regression algorithms are used to predict continuous values. They model relationships between variables. Examples include **Linear Regression**, **Logistic Regression**, and **Ridge Regression**.
#### Instance-Based Algorithms
These algorithms work by comparing new data points to previously seen examples. They are often referred to as "memory-based" or "lazy learners." Examples include **k-Nearest Neighbors (KNN)** and **Self-Organizing Maps (SOM)**.
#### Regularization Methods
Regularization techniques help prevent overfitting by adding constraints to the model. These are often extensions of regression algorithms. Common examples are **Lasso**, **Ridge**, and **Elastic Net**.
#### Decision Tree Learning
Decision trees are intuitive models that split data based on features. They are used for both classification and regression. Popular algorithms include **CART**, **ID3**, **C4.5**, and **Random Forest**.
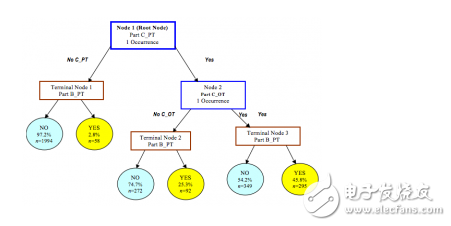
#### Bayesian Methods
Bayesian algorithms rely on probability theory. They're particularly useful for classification tasks. Examples include **Naive Bayes**, **AODE**, and **Bayesian Networks**.

#### Kernel-Based Algorithms
Kernel methods transform data into higher-dimensional spaces to make it easier to separate. The most famous example is **Support Vector Machine (SVM)**.
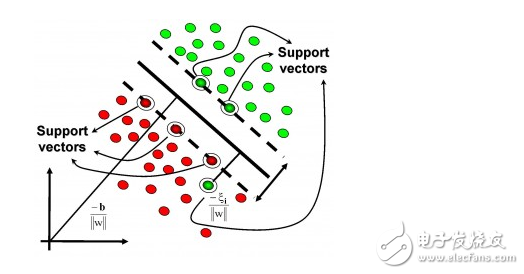
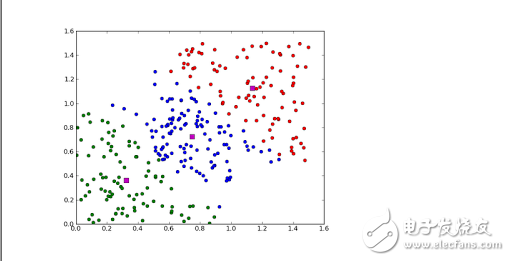
#### Clustering Algorithms
Clustering is the process of grouping similar data points together. It's used in customer segmentation, image compression, and anomaly detection. Common algorithms include **k-Means** and **Expectation Maximization (EM)**.
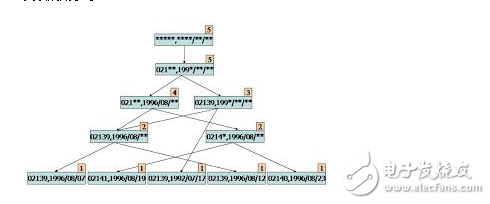
#### Association Rule Learning
This method finds relationships between variables in large datasets. It's widely used in market basket analysis. The **Apriori** and **Eclat** algorithms are typical examples.
#### Artificial Neural Networks
Neural networks mimic the human brain and are powerful for complex pattern recognition. They are used in image and speech recognition. Popular architectures include **Perceptron**, **Backpropagation**, and **Deep Neural Networks**.
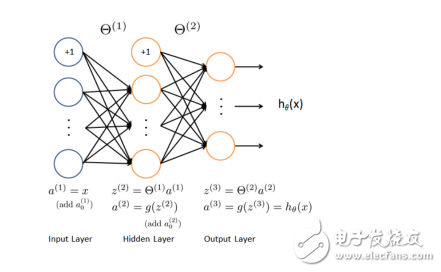
#### Deep Learning
Deep learning is a subset of neural networks that uses multiple layers to learn hierarchical representations of data. It's behind many breakthroughs in AI, especially in computer vision and natural language processing. Examples include **Convolutional Neural Networks (CNN)** and **Autoencoders**.
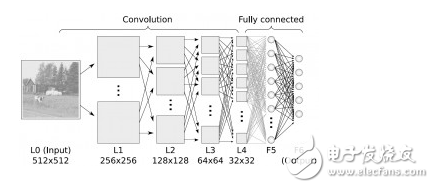
#### Dimensionality Reduction
This technique reduces the number of variables in a dataset while preserving important information. It's useful for visualization and improving model performance. Common algorithms include **PCA**, **LDA**, and **t-SNE**.
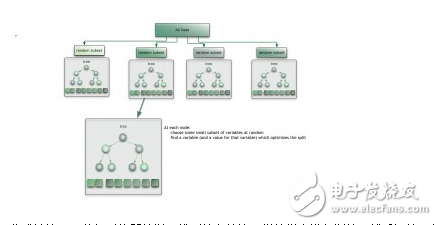
#### Ensemble Methods
Ensemble methods combine multiple models to improve predictive performance. Techniques like **Bagging**, **Boosting**, and **Stacking** are widely used. Popular algorithms include **Random Forest** and **Gradient Boosting**.
By understanding these categories and algorithms, you can make more informed decisions when choosing the right approach for your machine learning projects. Whether you're working on a classification problem, clustering, or deep learning, knowing the strengths and weaknesses of each algorithm will greatly enhance your ability to build effective models.
Beam Splitter,Dichroic Beam Splitter,Optical Beam Splitter Cube,Beam Splitter Cube
Danyang Horse Optical Co., Ltd , https://www.dyhorseoptical.com