**Summary**
Machine learning has become one of the most exciting and rapidly evolving fields in data science. It is widely used across various industries, from finance to healthcare, and even in everyday applications like recommendation systems or voice assistants. This article aims to provide a comprehensive overview of common machine learning algorithms, organized by learning methods and algorithm similarities, to help you better understand and apply them in your work or studies.

There are numerous machine learning algorithms, and it can be challenging to determine which one to use for a given problem. Some algorithms are variations of others, while some are designed for specific tasks. To make things clearer, we will categorize these algorithms based on two main aspects: the learning method and the similarity of the algorithms.
**Learning Methods**
Machine learning algorithms can be classified based on how they learn from data. Understanding this helps in choosing the right model for different types of problems.
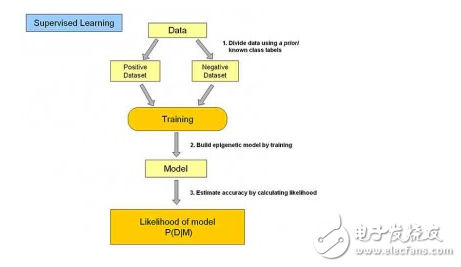
**Supervised Learning**
In supervised learning, the model is trained on labeled data, meaning each input example comes with a corresponding output. The goal is to learn a mapping from inputs to outputs so that the model can predict outcomes for new, unseen data. Common applications include classification and regression. Examples of algorithms include Logistic Regression, Decision Trees, and Neural Networks.
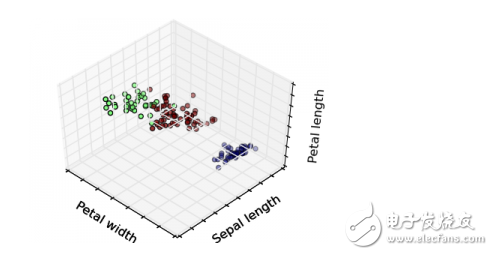
**Unsupervised Learning**
Unlike supervised learning, unsupervised learning deals with unlabeled data. The goal here is to find hidden patterns or structures within the data without predefined labels. Common applications include clustering and association rule mining. Algorithms such as k-Means and Apriori are often used.
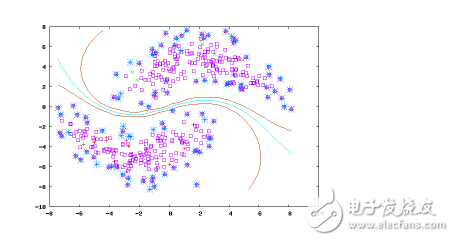
**Semi-Supervised Learning**
This approach combines both labeled and unlabeled data. It's particularly useful when there's a small amount of labeled data and a large amount of unlabeled data. Semi-supervised learning is often used in scenarios where labeling data is expensive or time-consuming. Algorithms like Laplacian SVM and Graph-based methods fall into this category.
**Reinforcement Learning**
In reinforcement learning, an agent learns to make decisions by interacting with an environment. The agent receives feedback in the form of rewards or penalties, which helps it improve its performance over time. This type of learning is commonly used in robotics, game playing, and autonomous systems. Popular algorithms include Q-Learning and Deep Reinforcement Learning.
**Algorithm Similarity**
Another way to classify algorithms is based on their structure and function. This helps in understanding which algorithms are best suited for particular tasks.
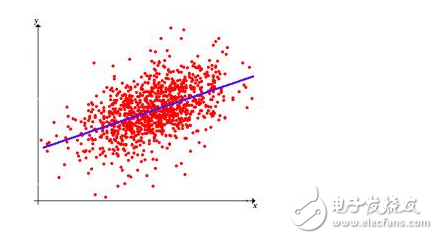
**Regression Algorithms**
These algorithms are used to predict continuous values, such as predicting house prices based on features like size, location, and number of rooms. Examples include Linear Regression, Logistic Regression, and Ridge Regression.
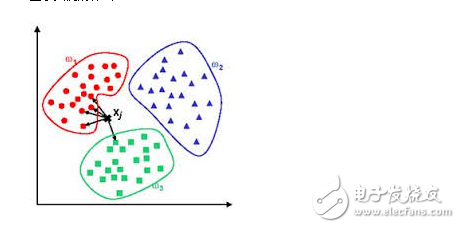
**Instance-Based Algorithms**
These algorithms rely on stored examples to make predictions. They compare new data points with previously seen instances to find the most similar ones. K-Nearest Neighbors (KNN) and Self-Organizing Maps (SOM) are typical examples.
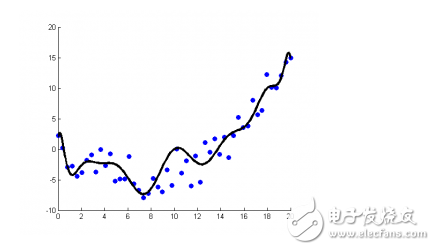
**Regularization Methods**
Regularization techniques are used to prevent overfitting by adding a penalty to the complexity of the model. Common approaches include Lasso, Ridge, and Elastic Net.
**Decision Tree Learning**
Decision trees split data based on feature values to create a tree-like model for decision-making. They are easy to interpret and widely used in classification and regression tasks. Popular algorithms include CART, ID3, and Random Forest.
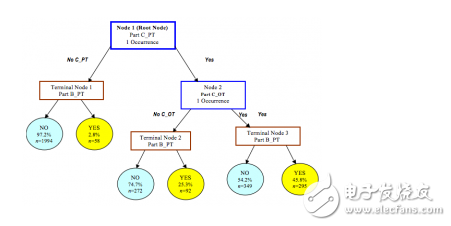
**Bayesian Methods**
These algorithms are based on Bayes' theorem and are used for probabilistic modeling. Naive Bayes and Bayesian Networks are commonly used for classification tasks.

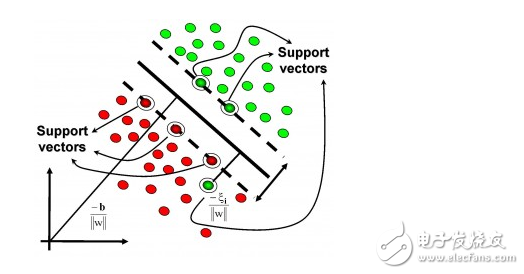
**Kernel-Based Algorithms**
Kernel methods transform data into higher-dimensional spaces to make it easier to separate or model. Support Vector Machines (SVM) are among the most popular kernel-based algorithms.
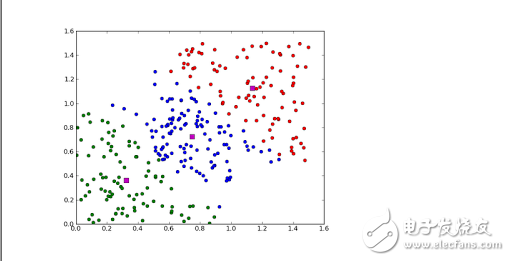
**Clustering Algorithms**
Clustering groups similar data points together without prior knowledge of the groupings. Common algorithms include k-Means and Expectation Maximization (EM).
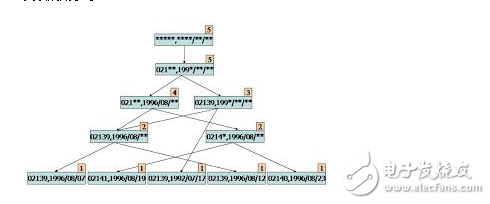
**Association Rule Learning**
This method discovers relationships between variables in large datasets. It is commonly used in market basket analysis. Apriori and Eclat are two well-known algorithms.
**Artificial Neural Networks**
Inspired by biological neural networks, these models are powerful tools for pattern recognition and complex data modeling. They are widely used in deep learning and include algorithms like Perceptron, Backpropagation, and Hopfield Networks.
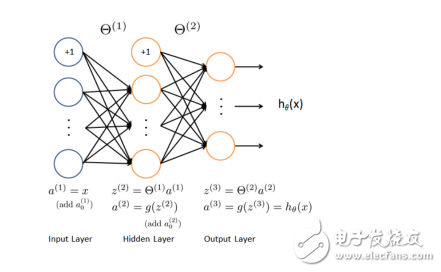
**Deep Learning**
Deep learning is a subset of neural networks with multiple layers, capable of learning complex representations from raw data. It has revolutionized fields like computer vision and natural language processing. Popular models include Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs).
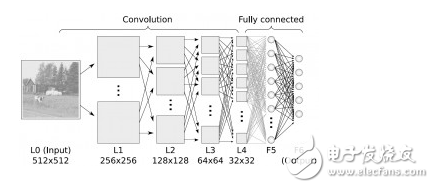
**Dimensionality Reduction Algorithms**
These algorithms reduce the number of variables in a dataset while preserving important information. Techniques like PCA and t-SNE are used for visualization and preprocessing.
**Ensemble Algorithms**
Ensemble methods combine multiple models to improve predictive performance. Techniques like Bagging, Boosting, and Stacking are widely used. Random Forest and Gradient Boosting are among the most popular ensemble algorithms.
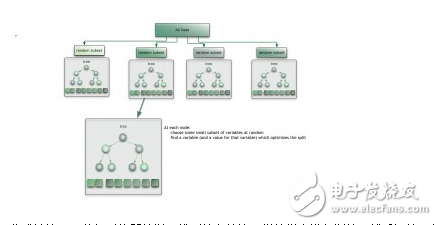
By understanding these different categories and their applications, you can better select and apply machine learning algorithms to solve real-world problems. Whether you're working on classification, regression, clustering, or deep learning, knowing the strengths and weaknesses of each approach is key to success.
Window Optical Lenses,Optical Lenses,Window Optical Lens,Calcium Fluoride Glass Window
Danyang Horse Optical Co., Ltd , https://www.dyhorseoptical.com